Documentation is important to understand the data/code. This post provides information about documentation, file naming and metadata.
Documentation
It is important to document your data, as it provides the contextual information needed to interpret the data. Data documentation includes information on the context of the data collection (project objectives and hypotheses), data collection methods (sampling, data collection process, analysis instruments used, software used to process the data etc), temporal and geographic coverage and by whom the data collection took place. Where multiple datasets or multiple versions of the same dataset are generated, the relationship between (the versions of) datasets should be clear.
Data organisation in spreadsheets (see also the Open Science Framework guidance)
File naming convention
Structure your file names and set up a template for this. It is very useful to start with the date (when the file was generated: YYYYMMDD) which will sort your files chronologically and also creates a unique identifier for each file. (It will be immediately clear if there are multiple files generated on the same day that will have to be given a version number –or “A, B”-, because otherwise overwriting would occurs if you store these files in the proper folder).
Examples:
20190607_ImPhys_RDMTemplate_v001_eng
Date or date range of experiment: YYYYMMDD
File type (or language such as the example above)
Researcher name/initials
Version number of file (v001, v002)
Don’t make file names too long (30-70 characters should do the trick)
Avoid special characters (?\!@*%{[<>) and spaces
You can explain the file naming convention in a README.txt file, so that it will also become clear to others what the file names mean.
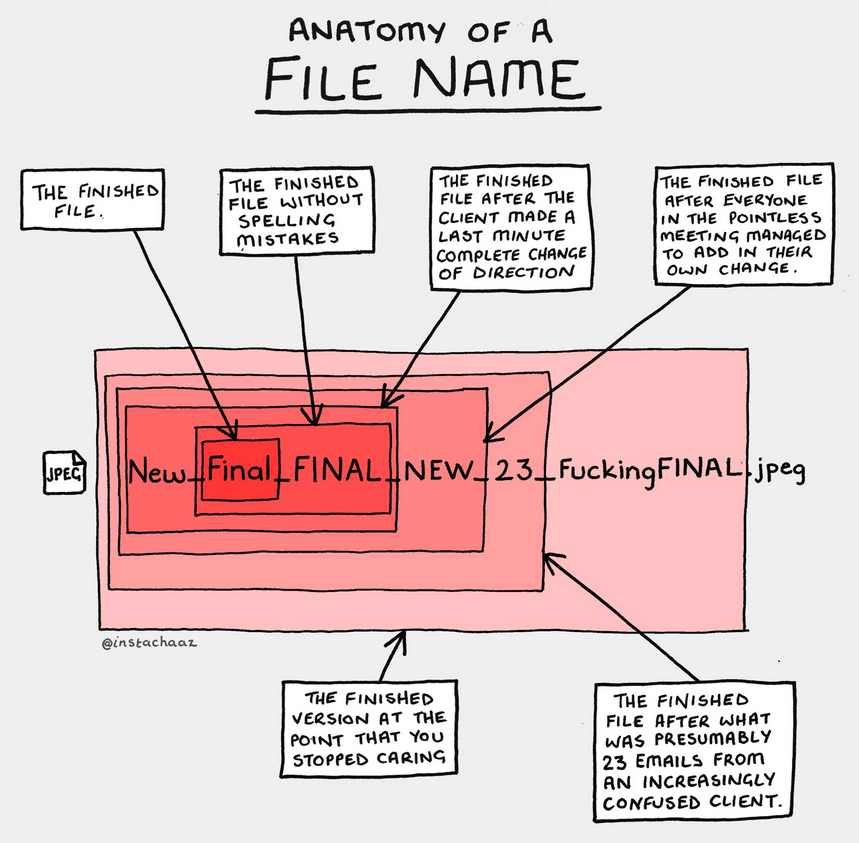
More information on file naming
8 step guide on how to set up your file naming convention
Danielle Navarro’s videos about file naming and project structure
Stanford’sbest practices for file naming
Bulk renaming tools (use with care!):
Windows: Ant Renamer, RenameIT, Bulk Rename Utility
Mac: Renamer, Name Changer
Linux: GNOME Commander, GPRename
Unix: Using the grep command to search for regular expressions
Metadata
Metadata is information about your data, such as the title of the dataset, the date, creator(s) and keywords that describe the data. Metadata standards with defined fields ensure machine readability. To look for disciplinary standards you can use the resources below:
• Research Data Alliance metadata directory
Tools available for metadata creation:
Frictionless: Datapackage Pipelines (see this presentation on YouTube)
Physical samples
Reference your samples: dates in notebooks + supplier’s name/code
Add any relevant notes:
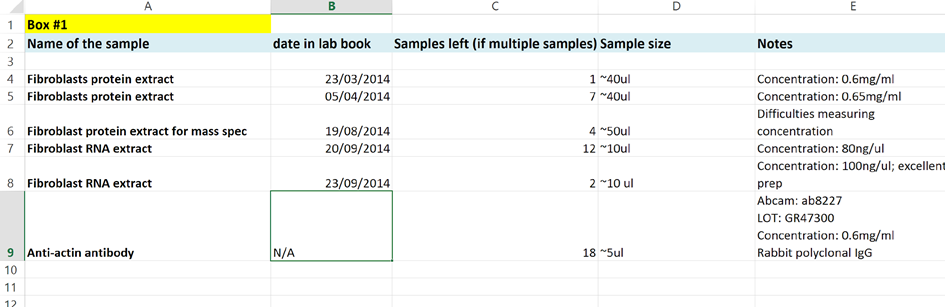
Electronic Lab Notebooks
TU Delft provides licenses for RSpace and eLABjournal.
You can also keep a digital copy in solutions such as OneNote, Obsidian or logseq.