This post is a summary of the publication by Gomes et al. 2022, on ‘Why don’t we share data and code? Perceived barriers and benefits to public archiving practices’.
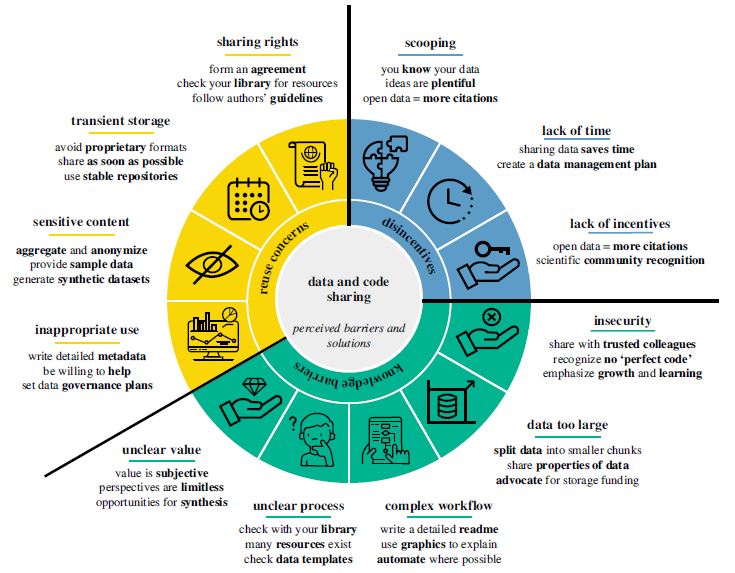
Knowledge barriers
Unsure about the process
Not sure about the data repository (see ‘How to share data’)
Accept that your practices will improve over time
Complex or manual workflows
Detail any manual data processing steps
Automation can improve workflows
Large data files
- 4TU.ResearchData allows for sharing of 1 TB, per researcher, per year
Insecurity
First share materials with trusted co-authors or peers in a safe environment (lab meetings or code clubs)
Getting feedback on code and documentation can improve its efficiency, clarity and utility beyond an individual project
There is no such thing as perfect code (Wilson et al. 2017)
Thee process of cleaning and reviewing data and code for publication will usually reveal errors before they are exposed publicly, which leads to higher-quality results
Foster an inclusive, kind environment that emphasizes growth and learning over criticism and shame. This will reduce individual insecurities and fear associated with publicly sharing research objects.
Do not see the value
value judgement is an inherently subjective rather than an objective decision.
there is a multitude of ways that a given set of data or code could be used by future generations of scientists, which is one reason why major funding agencies and many journals are now requiring open data and code products.
data are often useful in novel synthesis analyses that may explore research questions entirely unrelated to the original motivation of the data collection.
The more information we leave for future researchers, the better they will be able to progress our understanding of the world around us.
Reuse concerns
Inappropriate Use
All forms of scientific products can be misused — this is no reason not to publish these scientific products.
You can take steps to reduce or avoid the inappropriate use of data and code. By sharing detailed information or an accompanying data/software paper. This may include:
Thorough description of data and processes
Terms and conditions for reuse (license)
Limitations, assumptions and shortcomings of the work
Contact information
Rights
Data and code may have complex ownership involving multiple people and institutions, complicating sharing efforts. Sharing agreements made early in the research process can specify the plans for ultimately sharing data/code.
As TU Delft is your employer, it holds the right to any scientific research you work on
Research funding is public funding and should benefit the wider public
Sensitive Content
Not all data can be shared publicly (see types of confidential data)
In some cases, aggregating, generalizing or anonymizing data can be used to remove sensitive information (see Sharing Sensitive Data)
Sharing information about the dataset publicly is following the FAIR principles, and will make the information about the dataset more findable. Researchers can then contact you if they would like to access the dataset.
While open data is an important goal for advancing science, it must never perpetuate harm.
Transient storage
Disincentives
Scooping
Researchers publish most papers using their own datasets within 2 years of original publication, while papers that cite open datasets peak at 5 years after data publication (Piwowar and Vision 2013).
Preprint servers offer the ability to make first claim to a research projects
- pre-printed articles are already citable and benefit from increased viewership, citation rates and collaborations
Lack of time
Despite the upfront time required, sharing research data and code can ultimately save time for individual researchers and their collaborators, as well as for others who want to reuse it. Your most important collaborator is your future self.
Sharing data/code ensures that you always have access to it, regardless of switching institutions or computers.
The preparation of data and code should be considered as important as other publication tasks
Lack of incentives
Sharing data and code can:
increase visibility and recognition
initiate new collaborations
increase efficiency,
improve understanding of one’s own data and code
See ‘Why sharing data’ for some more benefits
Funders/publishers/research institutes increasingly require you to share data/code.