Why share data?
Prevent data loss/unfindable files
Can you still use data when people leave?
Recognition for all research outputs
Increased citations (Colavizza et al. 2020; Christensen et al. 2019; Piwowar et al. 2007; Piwowar and Vision 2013, Leitner et al. 2016)
Collaboration
Increases quality of scientific practice by increasing reproducibility and transparency of research
Cost/time efficient (see Cost of not having FAIR research data and Chan et al. 2014)
Prevents retractions
Reduces duplication efforts and facilitates data reuse (Martin et al. 2022)
Provides resources for training and education
Meeting institutional/funder/industrial requirements
The Coronavirus crisis is one of several global challenges which has highlighted the critical importance of making research data rapidly available for re-use, as well as curated to common standards (UNESCO).

Example: Majorana retraction
The authors of the 2018 article Quantized Majorana conductance have retracted this article. The authors were alerted to problems by two scientists in the same research area and then went on to re-examine their earlier measurements. In doing so, they found that the main conclusion had not been adequately substantiated.
Summary of the investigation by experts:
Authors selected data that supported the phenomenon they were looking for
Authors omitted data that could have raised questions about the conclusions
“It is a good thing that independent experts have looked at this as part of the integrity investigation,” says Tim van der Hagen, Rector Magnificus of TU Delft. ”Science always involves looking critically at results, questioning and challenging them.” source
- See the Majorana post for more articles/resources
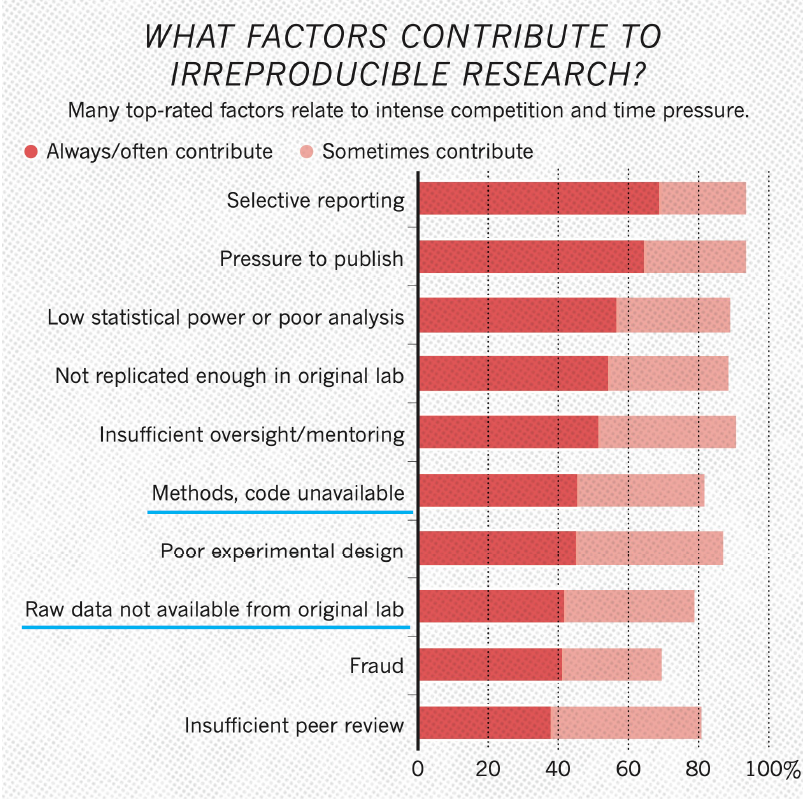
Reproducibility concerns
Does Chemical Engineering Research Have a Reproducibility Problem?
How Reproducible Are Isotherm Measurements in Metal−Organic Frameworks?
Does repeat synthesis in materials chemistry obey a power law?
Superconductivity scandal: the inside story of deception in a rising star’s physics lab
Data available upon request
Several studies indicate that data available upon request, is not actually available upon request:
Only “38% of the researchers sent their data immediately or after reminders” Vanpaemel et al. 2015
“We received only one of ten raw data sets requested.” Savage and Vickers 2009
“less than one-third of the contacted authors sent us the requested data.” Dutra dos Reis et al. 2021
” 73% of the authors did not share their data.” Wicherts et al. 2006
..” the odds of a data set being extant fell by 17% per year. In addition, the odds that we could find a working e-mail address for the first, last, or corresponding author fell by 7% per year.” Vines et al. 2014
” We received no response to 41.3% of our data requests.” - Tedersoo et al. 2021
” only 7/157 research articles shared their data sets, 4.5%.” Rowhani-Farid and Barnett 2016
“Data were recoverable online or through direct data requests for 30% of this sample. Data recovery declines exponentially with time since publication, halving every 6 years,….” Minocher et al. 2021
“Among articles stating that data was available upon request, only 17% shared data upon request.” Hussey 2023
“..we found raw data/code for 133 (47%) of those 283 preprints (15% of all analyzed preprint articles).” Strcic et al. 2022
only one (0.8%) out of 130 analyzed articles contained a direct link to the analyzed data (Gorman 2020)
Five selfish reasons to work reproducibly
Florian Markowetz provides five selfish reasons in his article and presentation (50 min) to work more reproducible. Reproducibility:
- helps to avoid disaster
- makes it easier to write papers
- helps reviewers see it your way
- enables continuity of your work
- helps to build your reputation
More information
- See also the posts on licensing, good enough FAIR software
- Encouragements and advice from several scientists and data stewards
- UKRN primer on Data Sharing
- APA Explains: Data Sharing
- NIH data management and sharing policy