6 Essentials for Research Data
Estimated time: 100 minutes
In this module, we start to dig deeper into RDM by introducing multiple topics concerning the essentials of RDM. At the end of this module you should be able to:
- Identify different types of research data
- Recognise what is considered confidential data in research
- Realise what RDM entails within a research project
- Recognise the responsibilities regarding RDM for TUD PhD candidates
- Store and back up the research data of your project in a secure manner
- Watch videos of TU Delft researchers telling you about the research data and confidential research data they work with
- If you work with personal data, read the information on the two linked websites
- Look at the research cycle image and the RDM questions you need to ask yourself at each step of your project
- Watch the video about data storage & infrastructure available at TU Delft
- Read the policy responsibilities
6.1 Research Data definition
Research data is any information that has been collected, observed, generated or created to validate research findings. Depending on the discipline you work in, research data can be collected or produced in different ways. You can capture them in real-time (sensors, images), you can collect them using laboratory instruments and they can derive from interviews or numerical simulations, among others. Research Data can be digital such as tabular data, videos, algorithms, scripts, transcripts, and codebooks. They can also be non-digital, for example, laboratory samples, sketchbooks, and prototypes.
In the next two videos, researchers from TU Delft tell us about the confidential data they work with and what RDM best-practice they follow:
- Sian Jones talking about collaboration with industry
- Wirawan Agahari talking about personal data in his research
Data can be classified in various ways, which is important for effective data management. The following categories provide a structured framework for understanding and working with research data:
6.1.1 Research Data categorised by its nature
Quantitative data refers to information that is numerical or measurable in nature. It involves collecting data through structured methods, such as surveys or experiments, and is analysed using statistical techniques.
Qualitative data is descriptive in nature, focusing on non-numerical information such as opinions, experiences, or behaviours. Qualitative data is typically collected through methods like interviews, observations, or open-ended survey questions and is analysed through thematic analysis or interpretation.
6.1.2 Research Data categorised by collection method
Experimental data: Data collected through controlled experiments where variables are intentionally manipulated and measured to establish cause-and-effect relationships.
Computational data: Data generated or processed using computational methods, such as simulations, numerical calculations, or machine learning outputs.
Observational data: Data obtained through direct observations of real-world phenomena, documenting existing behaviours, events, or characteristics without manipulation.
Derived/processed data: Data obtained by analysing or processing raw data. It is generated through calculations, algorithms, or transformations applied to the original data.
Research software/code: Computer programs or code developed and utilised in research activities to support data collection, analysis, modelling, or visualisation.
6.1.3 Research Data categorised by recording medium
Digital data including tabular data, images, videos, algorithms, scripts, transcripts, codebooks,
Non-digital data including laboratory samples, sketchbooks, prototypes.
6.1.4 Research Data categorised by file format
Research data can also be encountered in diverse formats during the data acquisition process reflecting the specific needs and characteristics of each scientific domain. The ability to access and reuse your data in the future depends on the chosen format. If the associated software/hardware is no longer used, data may become inaccessible. To ensure the longevity and accessibility of your research data, it is strongly recommended to use standard, exchangeable, or open file formats. 4TU.ResearchData provides a list of preferred file formats for which they guarantee long-term support.
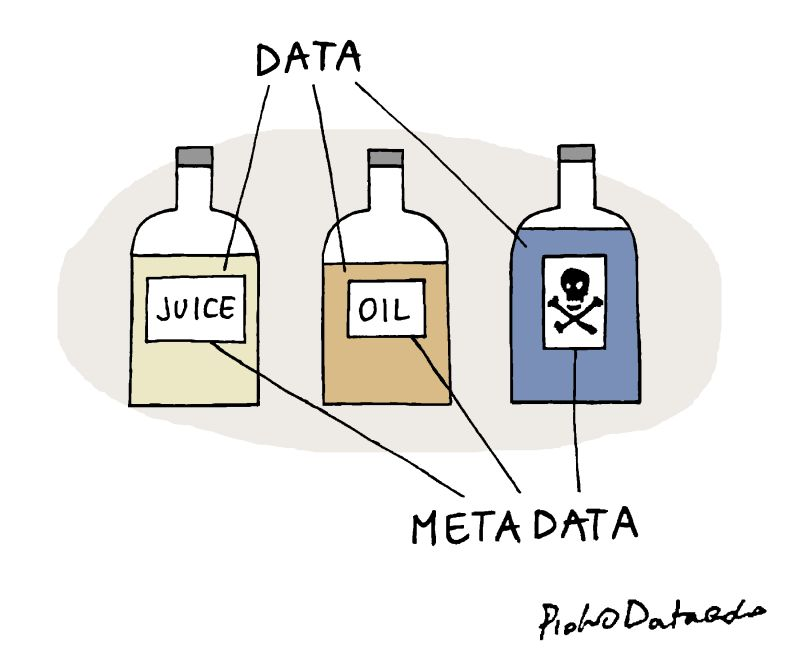
6.2 Confidential data
There are multiple types of confidential data that you might be working with during your research project. Some examples include:
- personal data (information about an identified or identifiable natural person, such as names, addresses and social security numbers)
- national security data (such as nuclear research)
- data falling under export control regulations
- confidential data received from commercial, or other external partners
- data related to competitive advantage (for example, patent, IP)
- data which could lead to reputation/brand damage (such as climate change, personal information, animal research)
- politically-sensitive data (such as research commissioned by public authorities, research on societal issues)
When working with confidential data, you need additional security measures for your data to make sure that they are not accidentally released.
6.3 Personal Data
Only read these materials if you work with personal data (data that can identify a person)
- TU Delft Information about privacy
- If you conduct research which involves human Research Subjects (where human participants are the source your research data), you will have to submit an application for approval to the TU Delft Human Research Ethic Committee.
- Personal data management - The Turing Way
When working with personal data, you will likely encounter the following definitions:
- Anonymised Data: Anonymisation involves the removal of personal information. Therefore anonymised data is often considered less sensitive and may have fewer data protection requirements.
- Pseudonymised Data: Pseudonymisation involves replacing identifiable information with pseudonyms or codes. While it reduces the risk of identifying individuals, it may still be subject to data protection regulations depending on the level of re-identification risk.
- De-identified Data: De-identification goes a step further by removing or modifying both direct and indirect identifiers, making it extremely challenging to re-identify individuals. De-identified data is generally subject to fewer data protection requirements.
6.4 Relevant RDM steps within a research project
In the following presentation you can go through a simplified cycle which can represent your project. Have a look at the RDM questions you might ask at each step of research.
6.5 Research Data infrastructure at TU Delft
In the next video we will go through the infrastructure provided centrally at TU Delft for storing, backup and sharing Research Data. Before starting the data collection/creation within your project, it is good to reflect where you will store and how you will back up the data. Selecting a storage and backup strategy will mean that data is safe during your research project, including in the case of unpredicted problems. Following good data storage practices protect you from data loss and facilitate effective collaborations. In this video, we will go through the infrastructure provided centrally at TU Delft for storing, backup and sharing Research Data. You should ask your supervisor if within your research group/department/ project there is a preferred approach for data storage and backup, or if there are customised solutions already in place.
02-4_Module-2 _Presentation _Data_StorageSharing (12 minutes)
6.5.1 TU Delft Resources:
6.6 RDM responsibilities
In this section we would like to make you aware of the responsibilities of TU Delft PhD candidates regarding Research Data Management.
These responsibilities are detailed in the University and Faculty Policies. It is very important for TU Delft that researchers follow best practices on Research Data Management (RDM). That is why since 2018 TU Delft has published a set of policies which provide a clear division of roles and responsibilities around RDM.
This Framework policy is accompanied by Faculty-specific data management policies, which provide more detailed requirements and guidelines for the disciplines associated with each Faculty.
At TU Delft, software is recognised as a valuable research output that needs to be well documented, preserved and, whenever possible, consistent with the FAIR principles. The TU Delft Research Software Policy provides a clear division of roles and responsibilities and sets out a simplified, streamlined process to help researchers share software.
6.6.1 Policy summary
This section summarises your responsibilities as a TU Delft/Applied Sciences PhD candidate:
- Developing a written data management plan (DMP) for managing research outputs within the first 12 months of the PhD study. (As part of the Go/No-Go meeting. For all PhDs starting from 1 January 2020 onwards.)
- Attending the relevant training in data management, for which credits can be obtained through the Graduate School.
- Ensuring that all data and code underlying completed PhD theses are appropriately documented and accessible for at least 10 years from the end of the research project, in accordance with the FAIR principles (Findable, Accessible, Interoperable and Reusable), unless there are valid reasons which make research data unsuitable for sharing. (For all PhDs starting from 1 January 2019 onwards.)
When sharing software:
- Use a data repository to obtain a DOI for the software. If you use 4TU.ResearchData your software will be automatically registered. If you use other repositories, such as Zenodo, you will have the register the software via PURE
- Choose one of the pre-approved licenses: MIT, BSD, Apache, GPL, AGPL, LGPL, EUPL, CC0.
See this slide for more details on how to share your software.